| Exercise 3.3 | Using Common Transformers |
| Data | 3-1-1 case location details (.xls hosted on FTP) |
| Overall Goal | Add a transformer to clean up schema Create a summary table |
| Demonstrates | Common transformer procedures |
| Start Workspace | C:\FMEData2018\Workspaces\IntroToDesktop\Ex3.3-Begin.fmw |
| End Workspace | C:\FMEData2018\Workspaces\IntroToDesktop\Ex3.3-Complete.fmw |
Your manager has some more requests for your workspace. The department wants to be able to provide a summary of the number of cases by department, by Local Planning Area, in addition to the original data with an edited schema. This summary table will help the city assess demand for different services in different areas of the city. In this exercise, we will use some attribute transformers to generate a summary table.
1) Start Workbench
Start Workbench (if necessary) and open the workspace from Exercise 3.2b. Alternatively you can open C:\FMEData2018\Workspaces\IntroToDesktop\Ex3.3-Begin.fmw.
2) Add a StatisticsCalculator
Add a StatisticsCalculator to your workspace and connect it to the AttributeValueMapper Output port. The StatisticsCalculator takes incoming features and generates desired summary statistics, e.g., takes the mean (average) of a numeric attribute:

Your manager has asked for a summary of the number of cases by department, by local area. We will fill in the StatisticsCalculator parameters to get this information:
| Parameter | Value |
|---|---|
| Group By | Department and Local Area |
| Attributes to Analyze | Case Type |
| Total Count Attribute | Cases |
Additionally, make sure you remove the values from all the other Calculated Attributes (Minimum Attribute, Maximum Attribute, etc.). You can do this by selecting the parameter and deleting it with the Delete or Backspace key, or by clicking the drop-down arrow and selecting Clear Value:
![]()
When finished, your parameters should look like this:
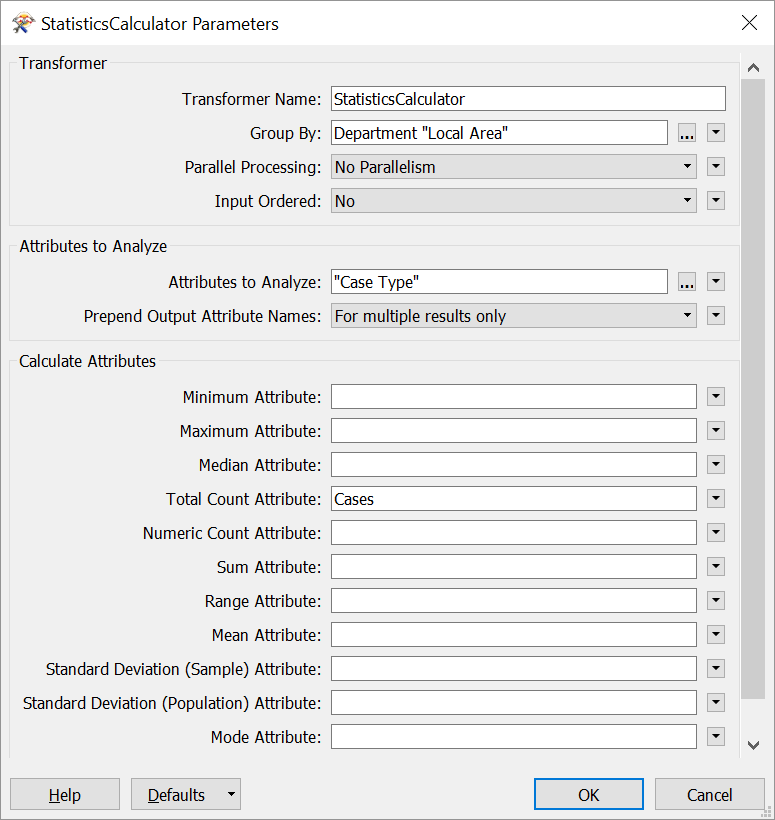
With these parameters, the transformer will add an attribute, Cases, to your data, which sums up the number of cases (our choice of Case Type is arbitrary, since it is just counting every feature that has a value). By setting Group By to Department and Local Area, we get the total count for each unique combination of department and local area.
Click OK and use "Run To Here" on the StatisticsCalculator type to summarize your data.
3) Inspect the Cache
Let's inspect the cache to ensure our data looks correct. Click on the green inspect cache icon on the Summary output port of the StatisticsCalculator. The StatisticsCalculator illustrates that transformers vary in the number of input and output ports they have. The Summary port outputs a summary table of the results, resulting in a new stream of features (here, 329), while the Complete and Cumulative ports add the results of the summary to every incoming feature (here, 93,223).
In the Data Inspector, you should see this in the Table View:

This result is a good start, but the schema of the Summary port output is quite different from our previous output. We can add another CSV feature type to output this summary table as a separate file.
4) Duplicate the CSV Writer Feature Type
Because your manager wants both the original data with a new schema and the summary table, we need two CSV writer feature types. Right-click the 311-requests feature type and click Duplicate. Move this new feature type (called 311-requests00 by default) above the original feature type and connect it to the Summary output port of the StatisticsCalculator:
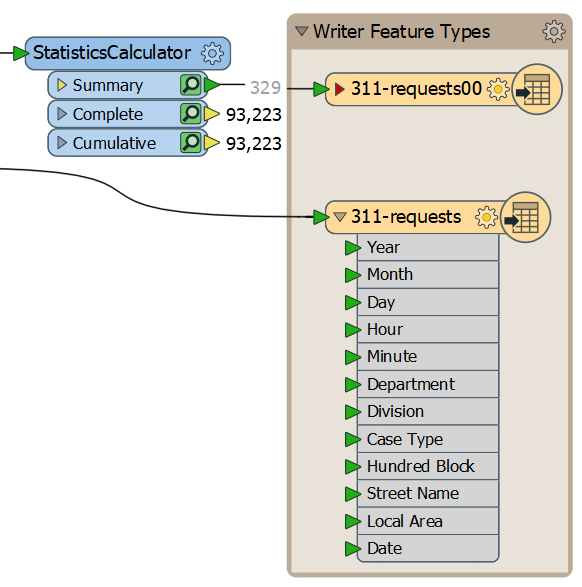
We need to edit the new summary feature type's schema. Double-click your 311-requests00 feature type to open its parameters. Change CSV File Name to 311-requests-summary:

Then, click on the User Attributes tab. We could manually remove the attributes we don't need. However, there is a faster way. Because we want our feature type to accept the parameters coming out of the StatisticsCalculator Summary port, we can change the Attribute Definition method from Manual to Automatic. Feature types using this mode will automatically adjust their schema to match connected features. Clicking it will edit the schema to contain only Department, Local Area, and Cases:

Now we have two CSV feature types being written, containing different structure (schema) and content (attribute values).
| CONGRATULATIONS |
By completing this exercise, you have learned how to:
|